
What Is Web Crawling?
Web crawling is the process of systematically browsing and collecting data from websites using automated programs called crawlers or bots. These crawlers follow links from one page to another, indexing or extracting information as they go. Search engines like Google rely on crawling to understand and organize the web. Businesses, researchers, and developers also use crawlers to gather data for analytics, product monitoring, price comparison, and market intelligence.
At its core, web crawling is about discovering and navigating web content at scale — something that would be impossible to do manually.
How Web Crawlers Work
A web crawler typically follows these steps:
- Start with a Seed URL
Crawlers begin with a list of starting pages. - Download the Page Content
The bot sends an HTTP request and retrieves HTML. - Parse the Page
It extracts meaningful elements, such as links, text, or structured data. - Follow Links to Discover More Pages
Every new link found is added to a queue for later crawling. - Store or Process the Data
The crawler may index text, extract pricing, track product rankings, analyze content changes, etc.
This forms a crawling loop, enabling large-scale navigation across websites.
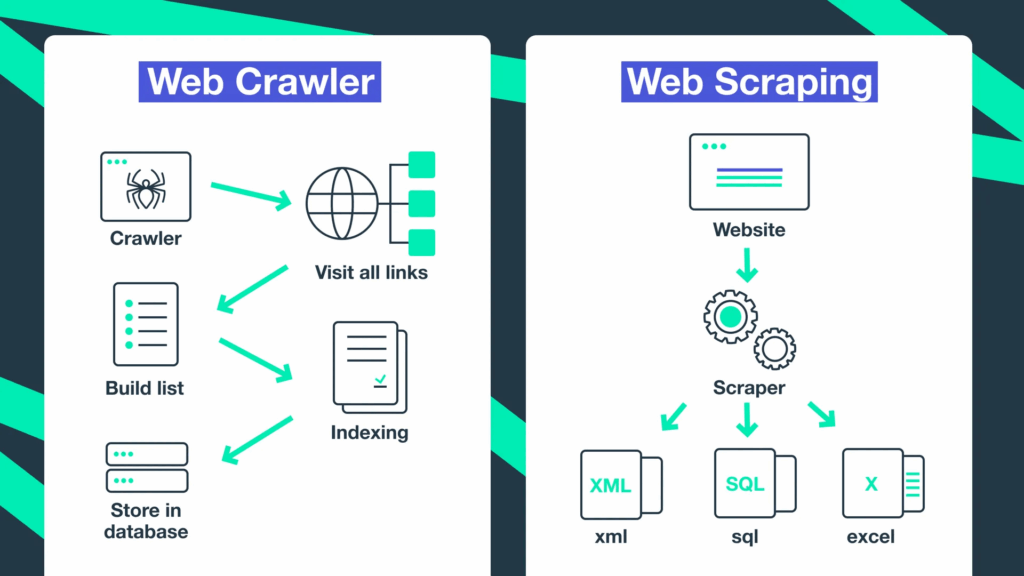
Web Crawling vs. Web Scraping — Are They the Same?
Although the terms are often used interchangeably, they refer to different concepts:
| Feature | Web Crawling | Web Scraping |
|---|---|---|
| Purpose | Discover and map website pages | Extract specific structured data |
| Output | URLs, site structure, content | Clean datasets (prices, reviews, text, etc.) |
| Typical Users | Search engines | Analysts, businesses, researchers |
In short: Crawling finds what to extract, while scraping extracts the data you need.
Common Use Cases for Web Crawling
| Industry | Application | Purpose |
|---|---|---|
| E-commerce | Product price monitoring | Tracking competitors’ pricing strategies |
| SEO & Marketing | Content indexing & SERP tracking | Performance analysis & optimization |
| Finance & Investment | News sentiment monitoring | Evaluating market trends |
| AI & NLP | Dataset collection | Training models with real-world text |
| Academic Research | Public data aggregation | Data-driven studies |
Web crawling is now a foundational technique behind search engines, pricing engines, AI datasets, and decision intelligence.
Challenges in Web Crawling
Real-world web crawling is not always straightforward. Websites implement various controls to manage bot traffic:
- IP Rate Limits
- Geo-Restrictions
- CAPTCHAs
- User-Agent Validation
- Content Obfuscation
If a crawler repeatedly visits a site from the same IP address or behaves too quickly, it may get blocked.
This is why web crawling at scale almost always requires proxies.
Why Proxies Are Essential for Web Crawling
Proxies act as intermediaries between your crawler and target websites. Instead of sending requests directly, your crawler routes traffic through IP addresses that look like real users.
Benefits of Using Proxies for Crawlers:
| Benefit | Description |
|---|---|
| IP Rotation | Prevents bans by cycling through different IPs |
| Geo-Targeting | View websites as if browsing from specific countries |
| Higher Success Rate | Reduces 403/429 errors and CAPTCHA triggers |
| Real-User Identity | Residential and ISP proxies look like normal traffic |
Without proxies, scaling web crawling becomes risky — crawlers get blocked, data gets incomplete, and automation fails.
Choosing the Right Proxy Type
| Proxy Type | Best For | Notes |
|---|---|---|
| Residential Proxies | Large-scale data collection | Real ISP-assigned IPs → high trust score |
| ISP / Static Residential Proxies | Fast, stable crawling | Constant IP ideal for session-based crawling |
| Datacenter Proxies | High-speed scraping tasks | More affordable but easier to block |
If your goal is reliable, undetectable crawling, residential or ISP proxies typically perform best.
QuarkIP provides all three categories, allowing teams to match proxy type to workload instead of relying on a single IP resource pool.
Best Practices for Efficient & Ethical Web Crawling
To maintain success and reduce blocks:
- Respect Robots.txt When Appropriate
It indicates which pages are crawl-friendly. - Set Human-Like Request Intervals
Avoid hammering sites with rapid requests. - Rotate IPs & User-Agents
Avoid repetitive patterns that trigger defenses. - Monitor Response Codes
Track errors to detect block patterns early. - Use Residential or ISP Proxies for High-Stake Targets
These proxies mimic real human traffic signatures.
Conclusion
Web crawling is a powerful technique powering search engines, competitive intelligence, AI training, and data-driven decision-making. But while crawling is straightforward in concept, executing it efficiently and reliably requires overcoming IP bans, anti-bot systems, and geo-based restrictions.
This is why proxy networks are integral to successful web crawling at scale.
If your team needs stable, high-success-rate crawling:
QuarkIP provides rotating residential, ISP, and datacenter proxies designed specifically for data collection tasks.





